Building a Governed Data Lake in the Cloud
Post By Dale T. Anderson, Talend Regional Manager, Customer Success Architect and Kent Graziano, Snowflake Senior Technical Evangelist
So you want to build a Data Lake? Ok, sure let’s talk about that. Perhaps you think a Data Lake will eliminate the need for a Data Warehouse and all your business users will merely lure business analytics from it easily. Maybe you think putting everything into Big Data technologies like Hadoop will resolve all your data challenges and deliver fast data processing with Spark delivering cool Machine Learning insights that magically give you a competitive edge. And really, with NoSQL, nobody needs a data model anymore, right?
Most of that is really just hype so we ask, how will you explain to your boss that your brand new Data Lake is really a Data Swamp, polluted with data from everywhere, incapable of getting meaningful data out to anywhere? We humbly suggest you avoid that scenario altogether and consider using Talend and the Snowflake Elastic Data Warehouse to build a better solution.
Before you begin building your successful Data Lake, let’s clarify a few common misconceptions:
- A Data Lake is (or should be)
- All business data located in one place
- An exposed data dictionary (or glossary) that governs lineage and history
- A fusion of Source data with meaningful Metadata models
- Useable for numerous business operational and reporting needs
- Scalable, adaptable, and robust; suitable for almost any business need
- A Data Lake is not (or what to avoid)
- The ‘New’ Enterprise Data Warehouse
- Necessarily Hadoop or NoSQL based
- Just another Data Silo with fast, easy access
- Able to eliminate data integration and processing needs
- The latest trend; It’s value can be very real
- Only for IoT, Analytics, and AI capabilities
Well then, why should you build a ‘Data Lake’? We believe the main purpose of a Data Lake is to provide full and direct access to raw (unfiltered) organizational data as an alternative to storing varying and sometimes limited datasets in scattered, disparate data silos. For instance, say you have ERP data in one DataMart and Weblogs on a different file server; when you need a query that joins them together, some complex federation scheme (and additional software) is often required: A real pain, right? Ideally, the Data Lake would allow you to put all that data into one big repository making it readily accessible for any query you might conceive.
With a properly architected and governed Data Lake you could in fact load all of the data you care about together so every business use case can be easily and seamlessly supported. The ability to provide everything from traditional business intelligence reporting and analytics, to data exploration, discovery, and experimentation from your data science team could hoist you up as the Boss’s hero.
Ok, you ask, what is needed to build a successful ‘Data Lake’? Like most complex software projects involving massive amounts of data the first thing to do is take it seriously. We do! The potential benefits of a properly constructed Data Lake far outweigh the build-out effort so setting proper expectations is paramount. Measurable results may not surface immediately. You need to take the time to architect, design, and plan these efforts and timeline; sure use an ‘Agile’ approach: That can work! But set goals on the horizon and march to a cadence your team can support, adjust and adapt as you go. You’ll get there.
And like any complex software project involving massive amounts of data you must carefully consider three important things:
- PEOPLE
- Involve ‘All’ business stakeholders — it is their data!
- Engage technical experts as needed — or become them!
- PROCESS
- Develop and follow proper, pliable, guidelines — write them down!
- Establish Data Governance as the rule — not the afterthought!
- Incorporate proper Methodologies — SDLC and Data Modeling!
- Use Best Practices — be consistent!
- TECHNOLOGY
- Use the right tools — know how to use them!
Architecture and Infrastructure
When we talk about Data Lakes it is important to understand their power yet set proper expectations at the same time. Like any new lexicon, it is easy to misinterpret and/or misrepresent what a Data Lake is and/or how it should be exploited. Stakeholders may have their own notions (often prejudiced by industry hype that can sway unrealistic expectations) potentially resulting in a perfect storm of bad communication, the wrong technology, and unsuitable methodologies. We want you to avoid this.
Attaining a ‘Governed Data Lake’ essentially requires a robust data integration process to store data coupled with meaningful metadata containing proper data linage (e.g., load dates and source) to retrieve any data. Without these key attributes the likelihood of a ‘Data Swamp’ is very real. With this in mind let’s look at two important ecosystems:
- On-Premise
- This might involve RDBMS and/or Big Data infrastructures
- Usually Self-Managed with controlled/secure access
- Likely represents the SOURCE data, but not exclusively
- Traditional IT support, limitations, and delays
- Cloud
- This might involve SaaS applications
- Usually Hosted with user roles/permissions for access
- Process may be Cloud-2-Cloud, Cloud-2-Ground, or Ground-2-Cloud
- Low TCO, elastic flexibility, and global usability
On-Premise and In the Cloud
Depending upon your requirements how you build-out your architecture and infrastructure may vary. The benefits you may gain directly reflect your choices at the earliest stage of a Data Lake project. With Talend and Snowflake working together both of these ecosystems are possible. Let’s take a look:
Option 1 — Talend On-Prem and Snowflake in the Cloud
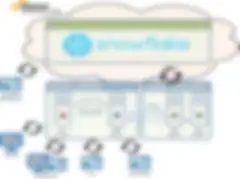
This first option depicts Talend being installed and running locally in your data center while Snowflake runs on a hosted AWS platform. Execution servers run your Talend jobs which connect to Snowflake and process data as needed.
This can present a good option when you prefer to support Talend services across a broad set of Source/Target data use cases where not everything you do is about the ‘Data Lake’.
Option 2 — Talend and Snowflake in the Cloud
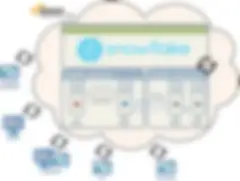
The second option moves the Talend installation into the cloud; perhaps hosted on AWS. Execution Servers run your jobs in the cloud, perhaps using some of the new AWS components now available for jobs that control elastic use of the AWS platform. These jobs can connect to Snowflake and/or any other Source/Data available from the Cloud ecosystem. This can present the best option when ingesting data directly into your Data Lake from files stored in the cloud and where users needing access to Talend are dispersed globally.
Data Integration and Processing
There is no avoiding brute force when filling a Data Lake with your data; getting data out can be even more taxing; therefore strong ETL/ELT data integration and processing capabilities are clearly essential. Let’s assume you already know that Talend’s software platform offers the canvas upon which you can paint your code to achieve these requirements. As a Java generation tool Talend’s capabilities for crafting robust process and efficient data flows is already proven. Talend software supports project integration, collaborative development, system administration, scheduling, monitoring, logging; well the list is long.
With well over 1000+ components available in the Talend Winter ’17 release (v6.3.1), crafting the solution to populate and manipulate your Data Lake just got a lot easier. Additional product capabilities provide data quality, governance, and preparation tools for the business analysts. Talend’s Metadata Management tool encapsulates details about your data in a glossary allowing you to maintain historical lineage as schemas change around you and supporting the generation of Talend jobs as needed.
Recently, Talend released the *NEW* Snowflake component you can use in your jobs. As this component has been written using the new Component Framework (TCOMP) it is only compatible with Talend v6.3.1 and above, so be sure to have the correct installation before you begin using it.
Data Warehouse as a Service (DWaaS) in the Cloud
What are we talking about when we say something is a Data Warehouse as a Service? First off we are talking about an RDBMS platform that has been designed specifically to support the type of queries associated with a data warehouse — that is analytic queries; aggregations. That being said, it must support tools that rely on standard SQL as the primary language. To support all the data needs of your Data Lake, it must also support ingestion and the ability to query semi-structured data just like the “Big Data” systems do.
Plus it needs to be offered “as a service” in the Cloud. That is, just like SaaS; no infrastructure to setup; Configuration and Administration all managed by the vendor. Also it needs to use an elastic “pay as you go” model, which in the case of DWaaS means you don’t pay for compute or storage resources you are not using!
We think you need to care about this because a true DWaaS will help you achieve the goal of providing your organization with easy access to all the data they may need (that’s what a Data Lake is for, right?). In fact it achieves this not only through the ability to quickly load structured and unstructured data, but also providing easy access to that data to solve real business problems in a timely and cost effective manner. When this is architected to take advantage of the elasticity of the cloud, it will allow you to scale up and down, on demand, to support all the user concurrency you’ll likely ever need.
Snowflake is the only data warehouse built for the cloud exclusively as a service. Snowflake delivers the performance, concurrency, and simplicity needed to store and analyze all your organization’s data in one location. Snowflake’s technology combines the raw power of data warehousing, the flexibility of big data platforms, and the elasticity of the cloud at a fraction of the cost of traditional solutions.
One of the characteristics of Snowflake that makes it a great Data Lake platform is the innovative separation of storage from compute called the multi-cluster shared data architecture. Unlike current on-premises, legacy architectures, with Snowflake you can grow your storage footprint dynamically without regard to compute nodes. Likewise, when you need more compute power, you can dynamically resize your compute clusters to add more resources without having to buy more disk drives. Because of the separation, you can stream in terabytes, even petabytes, of raw data without worrying about how big your warehouse cluster is.
With separation of compute and storage you can configure multiple, independent compute clusters (called virtual warehouses) that access the same central store of data. With a successful multi-terabyte Data Lake, let your data scientists loose on a completely separate compute cluster just for them. They can use this cluster to power Machine Learning and/or SPARK Talend Jobs with no fear of impacting other users on the system. You can read about these capabilities here:
Another cool Snowflake feature is ‘Time Travel’. Snowflake automatically keeps track of changes to data over time (like a Type II Slowly Changing Dimension) which happens behind the scenes without setup or administration, making your Data Lake time variant from day one – you can query any data object at any point in time back up to 90 days in the past; perfect for doing comparisons of large, dynamic data sets.
With tools like these who would ever try to hand-code again?
SDLC and Best Practices
There is a significant opportunity for us to go deep on how to do all this. We’d like to. Yet we need to resist the urge to do it right now as it would be far too much for our simple blog to explain details about:
- Agile Enablement with Snowflake and Talend
- Data Lake Loading and Retrieval techniques with Spark
- Machine Learning models for predictive analytics
Instead, look for some follow-up Blogs on these topics in the future. We believe these details to be worth your consideration when crafting a successful Data Lake. Meanwhile, you may find the 4 part series on Talend Job Design Patterns and Best Practices interesting reading; or perhaps Saving Time and Space: Simplifying DevOps with Fast Cloning and Automatic Query Optimization from Snowflake. Regardless, consider carefully the approach for your infrastructure and implementation of a Data Lake. Some options available today with these technologies did not exist even a few years back.
Data Vault Modeling
One topic we feel is important to discuss here is the data modeling methodology you might employ in your Data Lake. Often over-looked or even ignored, this consideration is a key to your long term success. We have both written about the Data Vault approach in various blog pages: “What is a Data Vault and Why do we need it?” introduces you to the concepts and value of this innovative solution. For more information read “Data Vault Modeling and Snowflake”, or the “List of top Data Vault Resources”. We hope you find these helpful and informative.
The Data Vault approach to data modeling and business intelligence provides a very flexible, adaptable, and eminently automatable method for building out an Enterprise Data Ecosystem. It allows you to do so in a very agile way. One of the architectural underpinnings of Data Vault is the use of a staging area to hold the raw source data. In part, this supports the Data Vault’s principle of having re-startable load processes eliminating the need to return to the source systems to re-fetch data. At a recent presentation, it was pointed out that this sounds a lot like a Data Lake. Hmmm…..
If we follow the Data Vault recommendations of always recording the ‘Load Date’ and the ‘Record Source’ on every row, well then we start to see our concept of a ‘Governed Data Lake’ emerge. The next step is to make it a persistent staging area and apply ‘Change Data Capture’ techniques to the load process (preventing duplication). Now we really DO have a ‘Governed Data Lake’! Raw source data, coupled with metadata that has the added benefit of using considerably less storage than a typical Data Lake would (which tends to load full copies of source data over time without any meaningful mechanism to distinguish or easily retrieve useful information).

Take some time to review the Talend Data Vault Tutorial which is based on the model shown here. The tutorial shows how a 100% INSERT ONLY Data Lake can be processed using Talend jobs. Source code is included and a future release will incorporate a cloud implementation using the NEW Snowflake component mentioned above.
Conclusion
Don’t build a Data Swamp! Use modern cloud based DWaaS (Snowflake) and the leading-edge Data Integration tool (Talend) to build a Governed Data Lake that will be the foundation to your modern enterprise data architecture. Build it quickly, efficiently, and effectively with the highly adaptable Data Vault data modeling methodology instead of the traditional Star Schemas, which frankly represents the preverbal square peg for a round hole. The promise of a properly designed, constructed, and deployed Data Lake could deliver real value to your organization setting the stage for unrelenting success. Tell your Boss that!
If you would like to discuss the ideas presented here, in person, you can meet Dale and Kent at the 4th Annual World Wide Data Vault Consortium in Stowe, Vermont this May. Both Talend and Snowflake are sponsors of this event. Please register soon as seats are limited!
About the Author: Kent Graziano
Kent Graziano is a Senior Technical Evangelist for Snowflake Computing and an award-winning author, speaker, and trainer, in the areas of data modeling, data architecture, and data warehousing. He is a certified Data Vault Master and Data Vault 2.0 Practitioner (CDVP2), expert data modeler and solution architect with more than 30 years of experience, including two decades doing data warehousing and business intelligence (in multiple industries). He is an internationally recognized expert in Oracle SQL Developer Data Modeler and Agile Data Warehousing. Mr. Graziano has developed and led many successful software and data warehouse implementation teams, including multiple agile DW/BI teams. He has written numerous articles, authored three Kindle book (available on Amazon.com), co-authored four books, and has given hundreds of presentations, nationally and internationally. He was the technical editor for Super Charge Your Data Warehouse (the main technical book for DV 1.0). You can follow Kent on twitter @KentGraziano or on his blog The Data Warrior (http://kentgraziano.com)
